网站防止恶意登陆或防盗链的使用
使用场景:明明引用了一个正确的图片地址,但显示出来的却是一个红叉或写有“此图片仅限于
网站用户交流沟通使用”之类的“假图片”。用嗅探软件找到了多媒体资源的真实地址用下载软件仍然不能下载。下载一些资源时总是出错,如果确认地址没错的话,大多数情况都是遇上防盗链系统了。常见的防盗链系统,一般使用在图片、音视频、软件等相关的资源上。实现原理:把当前请求的主机与服务器的主机进行比对,如果不一样则就是恶意链接,反之则是正常链接。
不说了,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14String address=request.getHeader("referer"); //获取页面的请求地址
String pathAdd=""; //定义空字符串
if(address!=null){ //判断当前的页面的请求地址为空时
URL urlOne=new URL(address);//实例化URL方法
pathAdd=urlOne.getHost(); //获取请求页面的服务器主机
}
String address1=request.getRequestURL().toString(); //获取当前页面的地址
String pathAdd1="";
if(address1!=null){
URL urlTwo=new URL(address1);
pathAdd1=urlTwo.getHost(); //获取当前服务器的主机
}
if(!pathAdd.equals(pathAdd1)){ //判断当前页面的主机与服务器的主机是否相同
}根据这个原理 可以设置企业白名单
使用Request对象设置页面的防盗链
所谓的防盗链就是当你以一个非正常渠道去访问某一个Web资源的时候,服务器会将你的请求忽略并且将你的当前请求变为按正常渠道访问时的请求并返回到相应的页面,用户只有通过该页面中的相关操作去访问想要请求的最终资源。
例如,你有一个访问某资源的网址,但是你事先不知道这个网址是有防盗链的,那么当你输入该网址时你可能会发现,并没有马上跳转到你想要的资源页面而是一些无关的信息页面,但是就是在这些信息页面中你发现有一个超链接或是其他操作可以跳转到你所访问的最终资源页面。
这就是防盗链技术了,好了来看一个具体应用:
1 | Request.java |
1 | index.jsp |
- 例如我最终想要通过http://lcoalhost:8080/Request/Request这个网址获取到我想要的《东成西就》 的资源可是当我真正的输入这个网址时,却转到了: http://localhost:8080/Request/index.jsp这个页面
- 只有当你点击“喜剧片”这个超链接时才会真正的得到你想要的资源页面
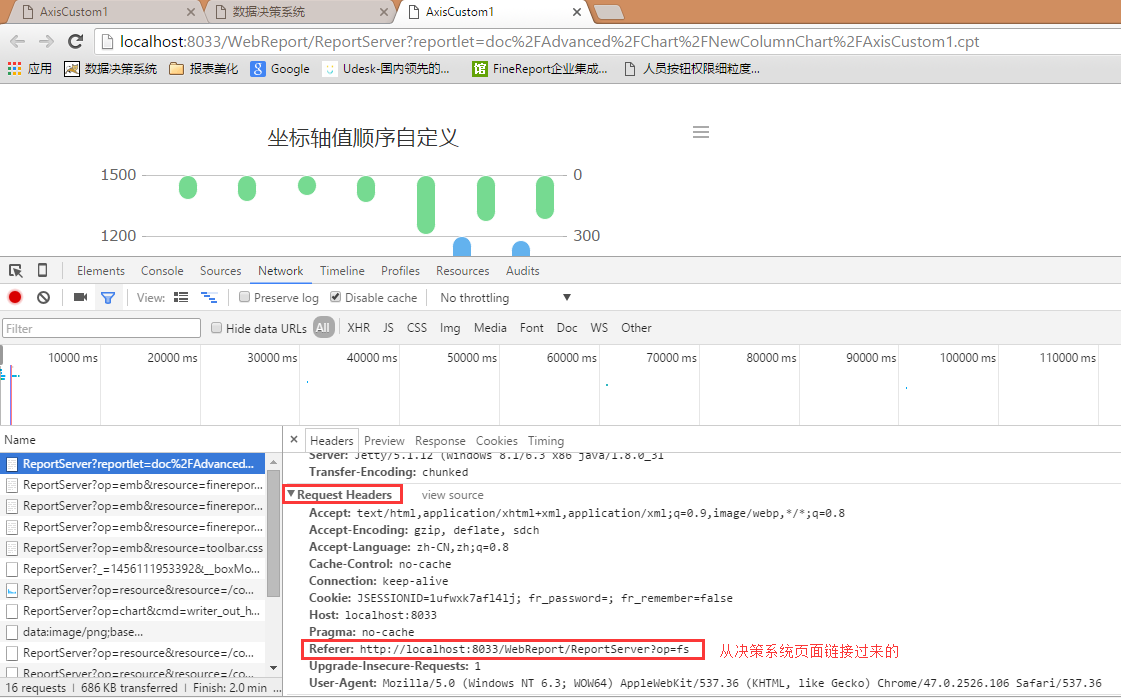
什么是Referer?
这里的 Referer 指的是HTTP头部的一个字段,也称为HTTP来源地址(HTTP Referer),用来表示从哪儿链接到目前的网页,采用的格式是URL。换句话说,借着 HTTP Referer 头部网页可以检查访客从哪里而来,这也常被用来对付伪造的跨网站请求。
什么是空Referer,什么时候会出现空Referer?
首先,我们对空Referer的定义为,Referer 头部的内容为空,或者,一个HTTP请求中根本不包含Referer头部。
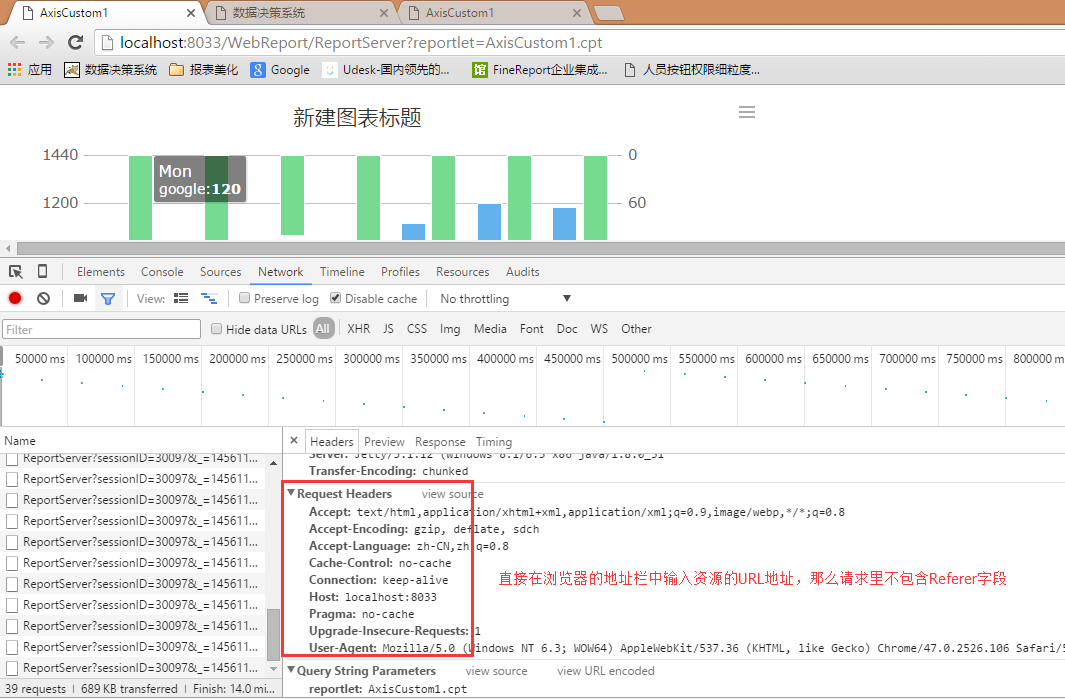
那么什么时候HTTP请求会不包含Referer字段呢?根据Referer的定义,它的作用是指示一个请求是从哪里链接过来,那么当一个请求并不是由链接触发产生的,那么自然也就不需要指定这个请求的链接来源。
比如,直接在浏览器的地址栏中输入一个资源的URL地址,那么这种请求是不会包含Referer字段的,因为这是一个“凭空产生”的HTTP请求,并不是从一个地方链接过去的。
- 在防盗链设置中,允许空Referer和不允许空Referer有什么区别?
- 在防盗链中,如果允许包含空的Referer,那么通过浏览器地址栏直接访问该资源URL是可以访问到的;
- 但如果不允许包含空的Referer,那么通过浏览器直接访问也是被禁止的。