MySQL一:架构体系
我们一般都不会去操作数据库本身,「而是通过SQL语句调用MySQL,由MySQL处理并返回执行结果」。那么SQL语句是如何执行sql语句的呢?
Sql语句执行过程图解:
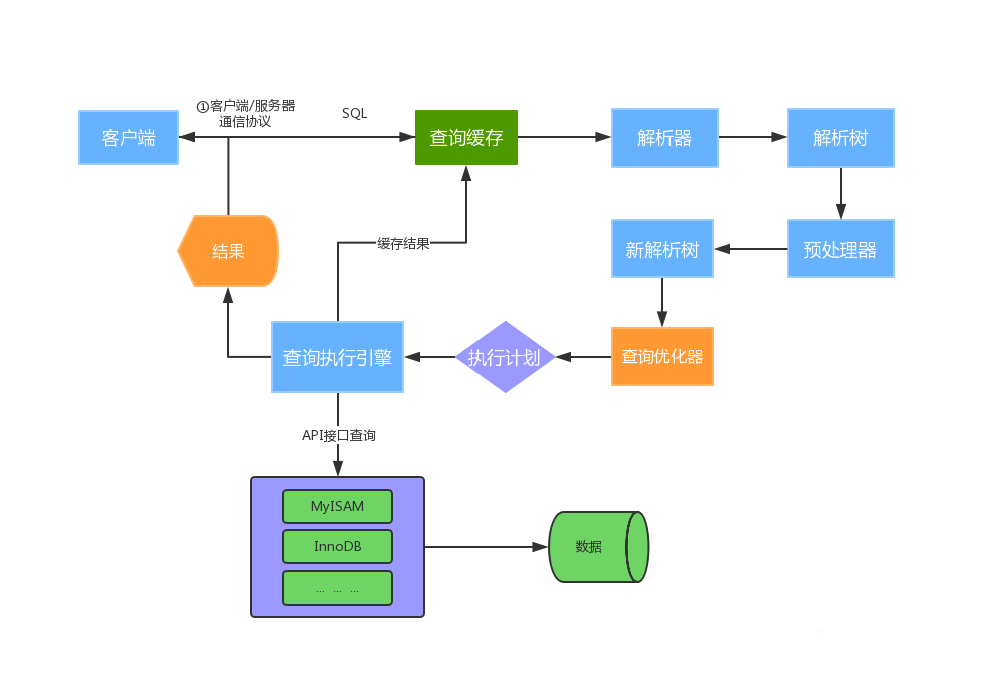
从图中可以看出sql的执行基本上分为五步:
- 「建立连接(Connectors&Connection Pool)」
- 「查询缓存(Cache&Buffer)」
- 「解析器(Parser)」
- 「预处理器(preprocessor)」
- 「查询优化器(Optimizer)」
- 「操作引擎执行 SQL 语句」
一、建立连接(Connectors&Connection Pool)
当客户端发送请求时,「客户端与服务器首先通过通信协议与MySQL的connectors建立连接。\「之后MySQL将收到请求」*暂存在连接池(connection pool)中,由处理器(Management Serveices & Utilities)管理。*「当该」**请求从等待队列进入到处理队列,管理器会将该请求丢给SQL接口(SQL Interface)。」**
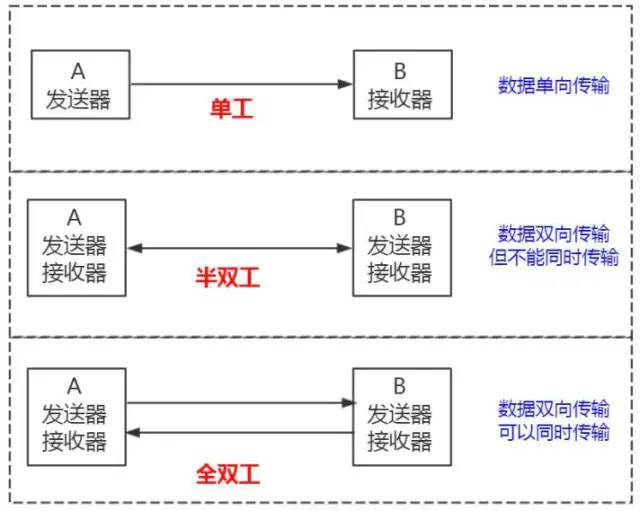
「MySQL客户端与服务端的通信方式是【半双工】」。所以对于每一个 MySQL 的连接,时刻都有一个【线程状态】来标识这个连接正在做什么。
「通讯机制」
「全双工」:能同时发送和接收数据。例如平时打电话。
全双工通信允许数据同时进行双向传输,即有两个信道。
全双工通信是两个单工通信方式的结合,要求收发双方都有独立的接收和发送能力。
「半双工」:指的某一时刻,要么发送数据,要么接收数据,不能同时。例如早期对讲机
半双工通信允许信号在两个方向上传输,但某一时刻只允许信号在一个信道上单向传输。
半双工通信实际上是一种可切换方向的单工通信。
「单工」:只能发送数据或只能接收数据。例如单行道
单工通信只支持信号在一个方向上传输(正向或反向),任何时候不能改变信号的传输方向。
「线程状态」
线程状态可以查看用户正在运行的线程信息,查询命令:
1
show processlist; #root用户能查看所有线程,其他用户只能看自己的

如图可以获取线程的详细信息:
Id:线程 ID ,结束线程可以使用以下命令
1
kill id
User:启动这个线程的用户;
Host:发送请求的客户端的 IP 和端口号;
db:当前命令在哪个库执行;
Command:该线程正在执行的操作命令
- Create DB:正在创建库操作;
- Drop DB:正在删除库操作;
- Execute:正在执行一个 PreparedStatement;
- Close Stmt:正在关闭一个 PreparedStatement;
- Query:正在执行一个语句;
- Sleep:正在等待客户端发送语句;
- Quit:正在退出;
- Shutdown:正在关闭服务器
Time:表示该线程处于当前状态的时间,单位是秒。
State:线程状态
- Updating:正在搜索匹配记录,进行修改;
- Sleeping:正在等待客户端发送新请求;
- Starting:正在执行请求处理;
- Checking table:正在检查数据表;
- Closing table:正在将表中数据刷新到磁盘中;
- Locked:被其他线程锁住了记录;
- Sending Data:正在处理 Select 查询,同时将结果返回发送给客户端;
Info:一般记录线程执行的语句,默认显示前100个字符。想看完整语句可以使用
1
show full processlist;
二、查询缓存(Cache&Buffer)
在sql接口接收到请求后,首先会在查询缓存中查找结果
- 开启查询缓存后,在查询缓存中找到完全相同的SQL语句,则将查询结果直接返回给客户端。
- 没有开启查询缓存或者没有找到完全相同的 SQL 语句。则会由解析器进行语法语义解析,并生成【解析树】。
2.1 开启查询缓存
「连接mysql服务」
1
2#mysql -h ip -u 用户 -P 端口 -p
mysql -h 127.0.0.1 -u root -P 3306 -p「查看是否开启查询缓存」
1
show variables like "%query_cache%";

上图中【query_cache_type】代表是否开启查询缓存
「0代表关闭查询缓存(显示OFF)」
「1表示始终开启查询缓存(显示ON)」
【当sql语句中有sql_no_cache关键词时不使用缓存】
如:select sql_no_cache user_name from users where user_id = ‘100’;
「2表示按需开启查询缓存(显示DEMAND)」
【代表当sql语句中有SQL_CACHE关键词时才缓存】
如:select SQL_CACHE user_name from users where user_id = ‘100’;
「开启查询缓存」
1
2
3
4
5
6
7
8#第一步:查询my.cnf的所在目录
[root@localhost www]# find / -name my.cnf
/etc/my.cnf
#第二步:编辑my.cnf 添加query_cache_type=1
[root@localhost www]# vim /etc/my.cnf
query_cache_type=1
#第三步:重启mysql 生效
[root@localhost www]# systemctl restart mysqld- 修改配置文件my.cnf开启查询缓存
设置变量开启查询缓存
1
set global query_cache_type = 1;
2.2 查询缓存失效
当sql语句满足下面条件时,即使开启查询缓存,以下SQL也不能缓存:
- 查询语句使用 SQL_NO_CACHE
- 查询的结果大于 query_cache_limit 设置
- 查询中有一些不确定的参数,比如 now()
三、解析器(Parser)
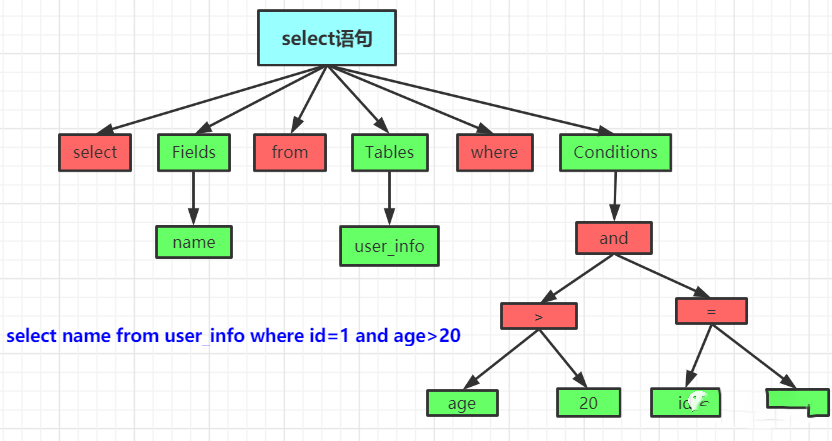
「当查询缓存没有命中时,客户端发送的SQL会被解析器进行语法解析,生成【解析树】,对sqlj进行语法分析」,生成解析树如下:
四、预处理器(preprocessor)
「当解析器的语法分析通过之后,预处理器会检查生成的解析树,解决解析器无法解析的语义」。它会检查表和列名是否存在,检查名字和别名,判断解析树的语义是否正确。预处理之后得到一个新的解析树。
这里留下一个问题,留待以后:
mysql预处理器和解析器生成的解析树有什么区别?
解析器只是语法解析 会生成一个解析树 预处理会检查表名 字段 权限啥的 然后生成一个新的解析树,
预处理会检查表名 字段 权限如果有问题 就直接报错了,那还生成解析树干啥?要是没报错,那他生成的解析树跟解析器的又有啥区别呢?
五、查询优化器
「当预处理器生成新的解析树之后,会进入优化器阶段,一条SQL的执行方式有很多种,数据库最终执行的SQL也不是客户端发送的SQL,但是最终返回的结果是相同的」。优化器会帮助我们选择一个最优的方式去执行sql.
比如:
表里面有多个索引的时候,决定使用哪个索引;
在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
5.1 查询优化器的作用
「查询优化器根据【解析树】生成不同的执行计划,然后选择一种最优的执行计划。MySQL是基于开销(cost)的优化器,选择使用开销最小的执行计划」。
1 | #查看查询的开销 |
「执行计划」
「mysql不会生成查询字节码来执行查询,而是生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。最终的执行计划包含了重构查询的全部信息」。
5.2 生成优执行计划策略
MySQL生成最优执行计划的有很多种策略,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)
5.2.1 静态优化(编译时优化)
「静态优化可以直接对解析树进行分析,并且完成优化」。优化器可以通过简单的代数变换将where 条件转换成另一种等价形式,「静态优化不依赖于特别的数值」
如where 条件中带入的一些常数等.静态优化再第一次完成后就一直有效,即使使用不同的参数重复执行查询也不会发生变化
「等价变换策略」
- 1=1 and a>1 优化后:a > 1
- a < b and a=5 优化后 b>5 and a=5
- 基于联合索引,调整条件位置
5.2.2 动态优化(运行时优化)
「优化count、min、max等函数」
InnoDB引擎min函数只需要找索引最左边
InnoDB引擎max函数只需要找索引最右边
MyISAM引擎count(*),不需要计算,直接返回
「提前终止查询」
使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
「in优化」
MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变 成 in (1,2,3)
六、操作引擎执行 SQL 语句
「在优化器生成最优的执行计划之后,会生成指令集,mysql会根据执行计划给出的指令逐步执行,并存储引擎的类型,调用对应的API接口与底层存储引擎缓存或者物理文件的交互,直到完成所有的数据查询。」
若开启用查询缓存
会将SQL语句和结果完整地保存到查询缓存(Cache&Buffer)中,以后若有相同的SQL语句执行则直接返回结果。
返回结果采用增量模式返回
- 服务器端不需要存储太多的结果,不会消耗过多内存。
- 客户端可以更快的获得返回的结果。
当查询不需要返回结果给客户端时,mysql仍然会返回这个查询的其他信息,如行数等
七、总结
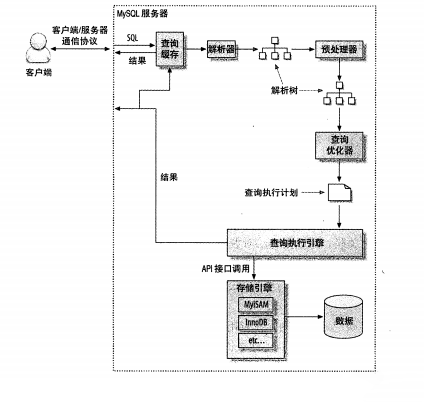
回顾一下mysql的运行机制的整体流程
- 首先客户端的请求会通过mysql的connectors与其进行连接,连接后请求会暂存在连接池(connection pool)中,由处理器(Management Serveices & Utilities)管理。
- 当请求从「等待队列进入到处理队列」,管理器会将该请求丢给SQL接口(SQL Interface)。
- SQL接口接收到请求后,会将请求进行hash处理并与缓存中的结果进行对比。如果匹配则返回缓存中的结果,否则解释器处理。
- 解释器接收SQL接口的请求,判断SQL语句语法是否正确,生成解析树。
- 解释器处理完,由预处理器校验权限,表名,字段名等信息。
- 优化器对针对最终的解析树产生多种执行计划,并选择最优的执行计划。
- 确定最优执行计划后,SQL语句交由存储引擎处理,存储引擎会在存储设备中取得相应的数据,并原路返回给客户端。